The Classification Process Դասակարգման գործընթաց

Reading time
Content
Պատկերի դասակարգման գործընթացը սովորաբար ներառում է հինգ քայլ (նկար 8).
ա) ՀԶ պատկերների ընտրություն եւ նախապատրաստում - դասակարգման նպատակին համապատասխան սենսորի, ձեռքբերման ամսաթվ(եր)ի եւ ալիքի երկարության գոտիների ընտրություն: Սա ներառում է շերտերի կորելյացիայի դիտարկումը, որտեղ երկու շերտում միմյանց նմանսպեկտրալ արտացոլումը կարող է հանգեցնել տեղեկատվության ավելցուկի եւ խաթարել դասակարգումը։
բ) Խմբերի (կլաստերների) սահմանումը հատկանիշների տարածությունում -սա կարող է իրականացվել վերահսկելի կամ անվերահսկելի մեթոդներով: Վերահսկելի դասակարգման դեպքում օպերատորը սահմանում է խմբերը ուսուցման ընթացքում: Ի տարբերություն դրա, անվերահսկելի դասակարգումը ներառում է խմբավորման ալգորիթմ, որը ինքնաշխատ կերպով նույնականացնում եւ որոշում է հատկանիշների տարածությունում խմբերի քանակը։
գ) Դասակարգման ալգորիթմի ընտրություն - երբ սպեկտրալ դասերը սահմանվել են հատկանիշների տարածության մեջ, օպերատորը պետք է որոշի, թե ինչպես են պիքսելները (հիմնվելով դրանց հատկանիշների վեկտորների վրա) վերագրվելու դասերին: Վերագրումը կարող է հիմնված լինել տարբեր չափանիշների վրա։
դ) Փաստացի դասակարգման իրականացում - երբ ուսուցման տվյալները հաստատվել են եւ դասակարգիչի ալգորիթմն ընտրվել է, հնարավոր է իրականացնել փաստացի դասակարգում։ Սա նշանակում է, որ իր DN-ների հիման վրա պատկերի յուրաքանչյուր «բազմաշերտ պիքսել» վերագրվում է նախապես սահմանված դասերից մեկին (նկար 9):
ե) Արդյունքի ստուգում - դասակարգված պատկերն ստեղծելուց հետո գնահատում են դրա որակը՝ այն համեմատելով էտալոնային տվյալների հետ (հիմնային ճշմարտություն): Սա պահանջում է նմուշառման տեխնիկայի ընտրություն, սխալների մատրիցի ստեղծում եւ սխալների պարամետրերի հաշվարկ:
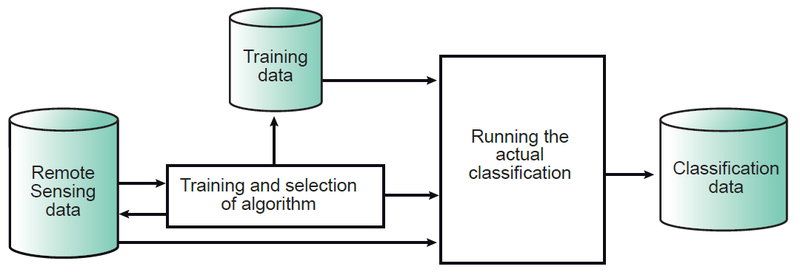
Նկար 8. Դասակարգման գործընթացը. ամենակարեւոր բաղադրիչներն են՝ ուսուցումն ու ալգորիթմի ընտրությունը

Նկար 9. Բազմաշերտ պատկերի (ա) դասակարգման արդյունքը՝ պատկեր է, որտեղ յուրաքանչյուր պիքսել վերագրվում է որոշակի թեմատիկ դասի (բ)
Վերահսկելի դասակարգում - Օպերատորը սահմանում է դասերի սպեկտրալ բնութագրերը՝ նույնականացնելով «նմուշային (բնորոշ) տարածքները (ուսուցման տարածքները)»: Սա պահանջում է, որ օպերատորը «ծանոթ լինի հետաքրքրության տարածքին» եւ իմանա, թե որտեղ գտնել դասերը, հաճախ՝ դաշտային դիտարկումների միջոցով: Սկզբունքն այն է, որ պիքսելը վերագրվում է դասին՝ հատկանիշների տարածության մեջ համեմատելով դրա հատկանիշների վեկտորը այս նախապես սահմանված խմբերի հետ: Ուսուցման նմուշները հավաքվում են «հետաքրքրության շրջանների (ROI)» միջոցով, որոնք ընտրվում են համասեռ տարածքներում:
Վերահսկելի դասակարգման դեպքում դասերի վիճակագրական տվյալները կարեւոր դեր են խաղում հատկանիշների տարածության մեջ խմբերի բնութագրման գործում, որի հիման վրա իրականացվում է պատկերների դասակարգումը: Վիճակագրական տվյալները (օրինակ՝ միջին արժեքները եւ կովարիացիոն մատրիցները) գնահատվում են փորձանմուշներից: Վերջիններս պետք է լինեն դասի ներկայացուցիչ եւ ծածկեն դրա փոփոխականությունը դասի ներսում:
Խմբերը չպետք է համընկնեն միմյանց հետ կամ միայն մասամբ. հակառակ դեպքում հուսալի բաժանումն անհնար է: Որոշակի տվյալների բազմության համար որոշ դասեր կարող են ունենալ զգալի սպեկտրալ համընկնում, ինչը, սկզբունքորեն, նշանակում է, որ այս դասերը չեն կարող տարբերակվել պատկերների դասակարգմամբ: Լուծումները ներառում են այլ սպեկտրալ գոտիների եւ/կամ տարբեր ժամանակներում ստացված պատկերների ավելացում (նկար 10):
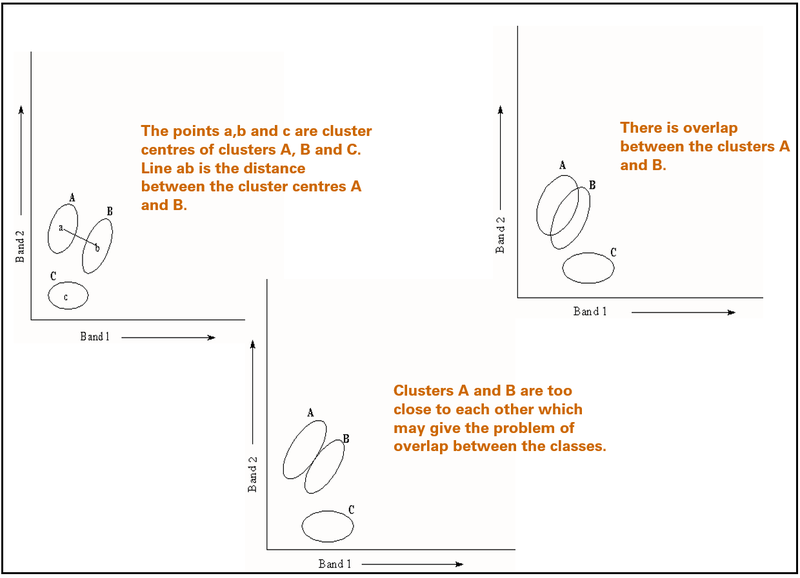
Նկար 10. Կլաստերների եւ համընկնումների պատկերում։ Ցույց է տալիս խմբերի սպեկտրալ համընկնումները վերահսկելի դասակարգման առանձնահատկությունների տարածությունում։ Սպեկտրալ համընկնումը տեղի է ունենում, երբ այն խմբերը, որոնք ներկայացնում են տարբեր դասեր, հստակորեն չեն առանձնացվում հատկանիշների տարածությունում։ Սա նշանակում է, որ մեկ դասի համար պիքսելների արժեքների որոշ համակցություններ կարող են ընկնել այն շրջանի սահմաններում, որը հիմնականում զբաղեցրել է մեկ այլ դաս, ինչը դժվարացնում է դրանց տարբերակումը։
Վերահսկելի դասակարգման դեպքում ստացված կլաստերային վիճակագրությունն այնուհետեւ կիրառվում է ամբողջ պատկերը դասակարգելիս՝ օգտագործելով ընտրված դասակարգման ալգորիթմը։
Անվերահսկելի դասակարգումն օգտագործվում է, երբ տարածքի վերաբերյալ գիտելիքները բավարար չեն կամ դասերը սահմանված չեն։ Կլաստերացման ալգորիթմներն ինքնաշխատ կերպով «բաժանում են առանձնահատկությունների տարածությունը մի քանի խմբերի»՝ հիմնվելով սպեկտրալ նմանությունների վրա։ Տարածված մոտեցումը ենթադրում է, որ օգտատերը սահմանում է խմբերի առավելագույն քանակը, այնուհետեւ համակարգիչը գտնում է կամայական միջին վեկտորներ որպես կլաստերի կենտրոններ, պիքսելները վերագրում է ամենամոտ կենտրոնին եւ վերահաշվարկում է կենտրոններն իտերատիվ կերպով, մինչեւ դրանք կայունանան։ Շատ քիչ կետեր ունեցող խմբերը հնարավոր է վերացնել կամ միավորել։
Նկար 11-ը պատկերում է տվյալների բազմության վրա կիրառված կլաստերացման ալգորիթմի արդյունքները։ Նկատի ունենալ, որ կլաստերային կենտրոնները համընկնում են առանձնահատկությունների տարածության բարձր խտության տարածքների հետ։
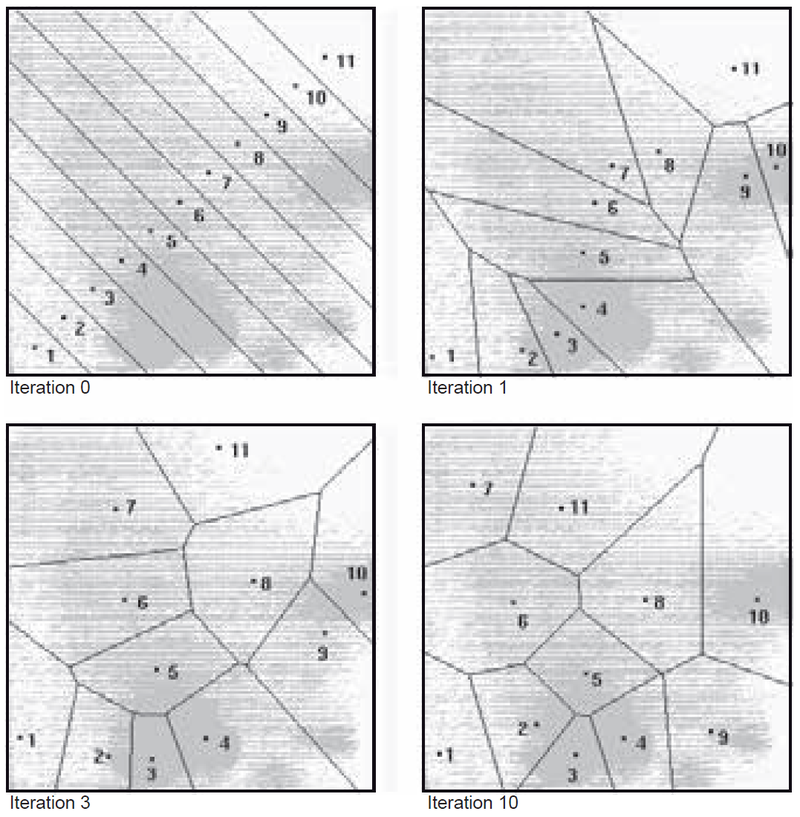
Նկար 11. Իտերատիվ կլաստերացման ալգորիթմի հետագա արդյունքները նմուշային տվյալների բազմության վրա։
Դասակարգման ալգորիթմներ
Վերապատրաստման նմուշային բազմությունների որոշումից հետո պատկերի դասակարգումը կարող է իրականացվել դասակարգման ալգորիթմի կիրառմամբ։ Դրանք մի քանիսն են։ Ալգորիթմի ընտրությունը կախված է դասակարգման նպատակից եւ պատկերի ու նմուշային տվյալների բնութագրերից։ Օպերատորը պետք է որոշի, արդյո՞ք թույլատրվում է մերժման կամ անհայտ դաս։ Ստորեւ նկարագրվում է դասակարգման երեք ալգորիթմ։
Նախ բացատրում են տուփի դասակարգիչը. դրա պարզությունն օգնում է հասկանալ սկզբունքը։ Գործնականում տուփի դասակարգիչը գրեթե երբեք չի օգտագործվում. միջինից նվազագույն հեռավորությունը եւ առավելագույն հավանականության դասակարգիչներն առավել հաճախ օգտագործվում են։
Տուփի դասակարգիչ (մակարդակ-կտրվածք պիքսել) -ամենապարզը, սահմանում է յուրաքանչյուր գոտու եւ դասի վերին եւ ստորին սահմանները՝ ստեղծելով տուփանման տարածքներ առանձնահատկությունների տարածությունում։ Տուփի մեջ ընկած պիքսելներին տրվում է դրա պիտակը։ Կարող է հանգեցնել «անհայտ» կամ «մերժման» դասերի, իսկ համընկնումը կարող է առաջացնել կամայական վերագրում։ Տուփերի քանակը կախված է դասերի քանակից։ Դասակարգման ընթացքում մուտքային (երկշերտ) պատկերի յուրաքանչյուր հատկանիշային վեկտոր կստուգվի՝ պարզելու համար, արդյո՞ք այն տեղավորվում է որեւէ տուփում։ Եթե այո, ապա բջիջը կստանա այն տուփի դասի պիտակը, որին պատկանում է։ Տուփերից որեւէ մեկում չընկնող բջիջներին կհանձնվի «անհայտ դասը», որը երբեմն անվանում են նաեւ «մերժման դաս» (նկար 12)։
Տուփի դասակարգչի թերությունը դասերի միջեւ համընկնումն է։ Այդ դեպքում բջիջին կամայականորեն տրվում է առաջին տուփի պիտակը, որին այն հանդիպում է։
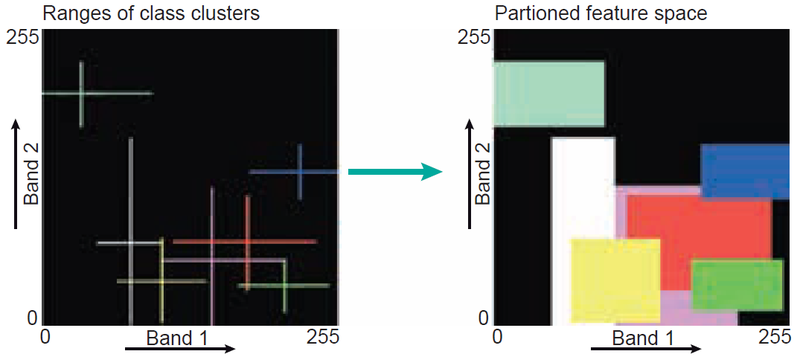
Նկար 12. Երկչափ հատկանիշների տարածության բաժանման դեպքում տուփային դասակարգման սկզբունքը
Միջինից նվազագույն հեռավորությունը (MDM) - պիքսելը վերագրում է այն դասին, որի կլաստերի կենտրոնը (միջին) ամենամոտն է գտնվում։ Հաշվի չի առնում դասի փոփոխականությունը։ Հնարավոր է սահմանել հեռավորության շեմ՝ հեռավոր կետերի վերագրումը կանխելու համար։
Նկար 13-ը պատկերում է, թե ինչպես է կլաստերի կենտրոնների հիման վրա հատկանիշների տարածությունը բաժանվում։ MDM դասակարգչի թերություններից մեկն այն է, որ կլաստերի կենտրոնից մեծ հեռավորության վրա գտնվող կետերը դեռ կարող են վերագրվել այդ կենտրոնին։
Այս խնդիրը կարելի է հաղթահարել՝ սահմանելով որոնման հեռավորությունը սահմանափակող շեմային արժեք։ Նկար 13-ը պատկերում է ազդեցությունը. կենտրոնից շեմային հեռավորությունը ցույց է տրված որպես շրջան։
MDM դասակարգչի մեկ այլ թերությունն այն է, որ հաշվի չի առնում դասի փոփոխականությունը. որոշ կլաստերներ փոքր եւ խիտ են, մինչդեռ մյուսները մեծ ու ցրված են։ Առավելագույն հավանականության դասակարգումը, սակայն, հաշվի է առնում դասի փոփոխականությունը։
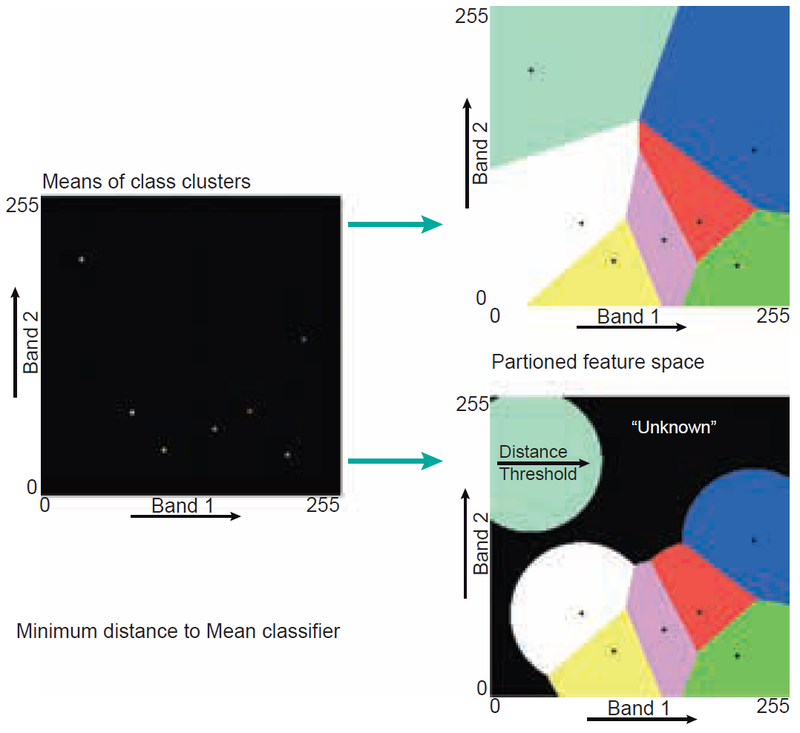
Նկար 13. Երկչափ իրավիճակում միջինից նվազագույն հեռավորության դասակարգման սկզբունքը: Որոշումների կայացման սահմանները ցույց են տրված շեմային հեռավորություն չունեցող (վերեւի աջ անկյունում) եւ շեմային հեռավորություն ունեցող (ներքեւի աջ անկյունում) իրավիճակների համար
Առավելագույն հավանականություն (ML) - առավել հաճախ կիրառվող, հաշվի է առնում ոչ միայն կլաստերների կենտրոնները, այլեւ կլաստերների ձեւը, չափը եւ կողմնորոշումը՝ հավանականության կիրառմամբ: Վերագրում է պիքսելը ամենաբարձր հավանականություն ունեցող դասին: ML դասակարգիչների մեծ մասը ենթադրում է, որ կլաստերների վիճակագրությունը հետեւում է նորմալ (գաուսյան) բաշխմանը:
Առավելագույն հավանականությունը նաեւ թույլ է տալիս օպերատորին սահմանել շեմային հեռավորություն՝ նշելով առավելագույն հավանականության արժեքը: Փոքր էլիպսը որպես կենտրոն միջին արժեքով նկարագրում է դասին պատկանելության ամենաբարձր հավանականություն ունեցող արժեքները: Կենտրոնը շրջապատող, աստիճանաբար մեծացող էլիպսները ներկայացնում են դասին պատկանելության հավանականության ուրվագծերը, որտեղ հավանականությունը նվազում է կենտրոնից հեռանալուն զուգընթաց: Նկար 14-ը պատկերում է առկա եւ առանց որոշումների կայացման սահմանները՝ շեմային հեռավորությամբ եւ առանց դրա սցենարների համար:
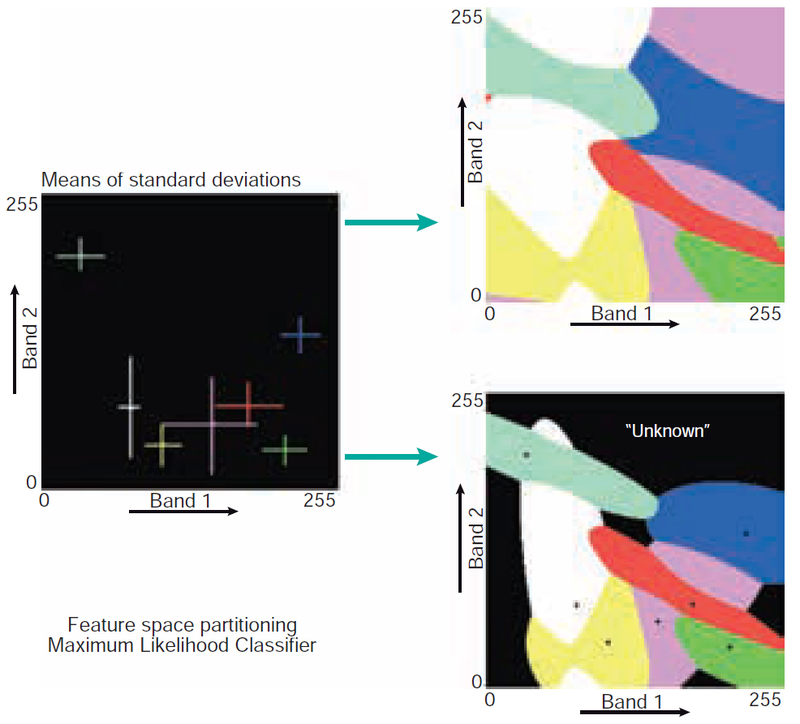
Նկար 14. Առավելագույն հավանականության դասակարգման սկզբունքը։ Որոշման սահմանները ցույց են տրված շեմային հեռավորություն չունեցող (վերեւի աջ անկյունում) եւ շեմային հեռավորություն ունեցող իրավիճակների համար (ներքեւի աջ անկյունում)
Իտերատիվ օպտիմալացում (միջինների ներհոսք/ISODATA) - գնահատում է սկզբնական կլաստերային կենտրոնները, պիքսելները վերագրում է ամենամոտ կենտրոնին, վերահաշվարկում է միջինները եւ կրկնում մինչեւ կենտրոնների կայունացումը։ Օգտատերը նշում է կլաստերների քանակը։ Թույլ է տալիս միավորել ու բաժանել կլաստերները՝ հիմնվելով նվազագույն կետերի կամ երկարացված ձեւերի նման չափանիշների վրա։
Դասակարգման արդյունքների վավերացում
Նպատակ. Ստուգել դասակարգման արդյունքի փաստացի որակը եւ հուսալիությունը:
Մեթոդաբանություն. Համեմատել դասակարգված արդյունքը «ճշմարիտ դասի» տվյալների հետ (գետնից տվյալներ կամ ավելի բարձր ճշտության աղբյուրներ, ինչպիսիք են օդալուսանկարները)։
Նմուշառման սխեմաներ. Փորձարկման համար պիքսելներ ընտրելու ռազմավարություններ, ներառյալ պարզ պատահական եւ շերտավորված պատահական նմուշառումները։ Ընտրությունները ներառում են ձեւավորումը, նմուշների քանակը (որոշվում է նմուշառման տեսությամբ) եւ նմուշի միավորի մակերեսը։
Սխալի մատրից (շփոթության/պատահականության/չնախատեսված հանգամանքների մատրից). համեմատությունը կատարվում է սխալի մատրից ստեղծելով, որից կարելի է հաշվարկել տարբեր ճշտության չափեր։ Փաստացի դասը նախընտրելի է ստանալ դաշտային դիտարկումներից։ Երբեմն, որպես էտալոն/չափանիշ օգտագործվում են ավելի բարձր ճշտությամբ աղբյուրներ, ինչպիսիք են անօդաչու թռչող սարքերից պատկերները։
Սխալի մատրիցը դասակարգված դասերը չափանիշային դասերի հետ համեմատող աղյուսակ է։
Հաստատման համար նմուշառումն իրականացնելուց եւ տվյալները հավաքելուց հետո կարելի է ստեղծել սխալի մատրից, որը երբեմն կոչվում է նաեւ շփոթության մատրից կամ պատահականության/չնախատեսված հանգամանքների մատրից (աղյուսակ 2): Աղյուսակում թվարկված է չորս դաս (A, B, C, D): Ընդհանուր առմամբ հավաքվել է 163 նմուշ: Աղյուսակը ցույց է տալիս, որ, օրինակ, իրական աշխարհում («չափանիշ») հայտնաբերվել է A-ի 53 դեպք, մինչդեռ դասակարգման արդյունքը տվել է 61-ը. 35 դեպքում դրանք համընկնում են։
Քարտեզագրման ճշգրտության առաջին եւ ամենատարածված չափանիշը ընդհանուր ճշտությունն է կամ ճիշտ դասակարգվածների համամասնությունը (PCC): Ընդհանուր ճշտությունը ճիշտ դասակարգված պիքսելների քանակն է (այսինքն՝ սխալի մատրիցի անկյունագծային բջիջների գումարը) բաժանած ստուգված պիքսելների ընդհանուր թվի վրա: Աղյուսակ 2-ում ընդհանուր ճշտությունը կազմում է (35 + 11 + 38 + 2)=163 = 53%: Ընդհանուր ճշտությունը ողջ արդյունքի համար տալիս է մեկ արժեք։
- Ընդհանուր ճշտություն. Ճիշտ դասակարգված նմուշների ընդհանուր քանակը բաժանած ընդհանուր նմուշների վրա։
- Բացթողման սխալ (II տիպի սխալ). Էտալոնային/չափանիշային դասից նմուշներ, որոնք դասակարգման մեջ սխալմամբ բաց են թողնվել այդ դասից (սխալմամբ դասակարգվել են որպես մեկ այլ դաս)։ Հաշվարկվում է սյունակի համար։ Համապատասխանում է արտադրողի ճշտությանը։
- Հրահանգման սխալ (I տիպի սխալ). Նմուշներ, որոնք դասակարգվել են որոշակի դասի մեջ ու պատկանում են այլ չափանիշային դասի։ Հաշվարկվում է տողի համար։ Համապատասխանում է օգտագործողի ճշգրտությանը։
- Օգտագործողի ճշտություն. Հավանականություն, որ որոշակի դասի պիտակավորված պիքսելը պատկանում է այդ դասին։
- Արտադրողի ճշտություն. Հավանականություն, որ չափանիշայաին դասը ճիշտ է ցուցադրվել/արտացոլվել որպես այդ դաս։
Աղյուսակ 2. Սխալների մատրից՝ ստացված սխալներով եւ ճշտությամբ, արտահայտված տոկոսներով։ A, B, C եւ D-ն վերաբերում են չափանիշային դասերին, իսկ a, b, c եւ d-ն՝ դասակարգման արդյունքում ստացված դասերին։ Ընդհանուր ճշտությունը 53% է։
| A | B | C | D | Total | Error of Ommission (%) | User Accuracy (%) | |
|---|---|---|---|---|---|---|---|
| a | 35 | 14 | 11 | 1 | 61 | 43 | 57 |
| b | 4 | 11 | 3 | 0 | 18 | 39 | 61 |
| c | 12 | 9 | 38 | 4 | 63 | 40 | 60 |
| d | 2 | 5 | 12 | 2 | 21 | 90 | 10 |
| Total | 53 | 39 | 64 | 7 | 163 | ||
| Error of Ommission | 34 | 72 | 41 | 71 | |||
| Producer Accuracy | 66 | 28 | 59 | 29 |